
I am currently a fourth-year Ph.D. student in the School of Automation at Southeast University, advised by Prof. Wankou Yang.
I have gained algorithm and research internship experience at ByteDance (2022), NIO (2023), Baidu (2024-2025), and Ant Group (2026). During my internship at Baidu, I was fortunate to work under the guidance of Dr. Jingdong Wang.
I have published 10+ first-authored papers in top international AI conferences and journals, including TPAMI, TIP, ICML, ICCV, CVPR, and NeurIPS. My work has received 1,000+ citations on Google Scholar. My research interests include MLLMs, Agentic RL, Visual Grounding, Video/Image Referring Segmentation, and Agentic Search.
Please feel free to contact me at 869906992@qq.com for questions, discussions, or potential collaborations.
🔥 News
- 2026.07: 🎉 Our co-first-authored paper ScanFocus has been accepted to ECCV 2026. The code is publicly available.
- 2026.07: 🚀 Our technical report SimpleSearch-VL is released, exploring efficient, reliable, and practical multimodal agentic search. Project/Repo
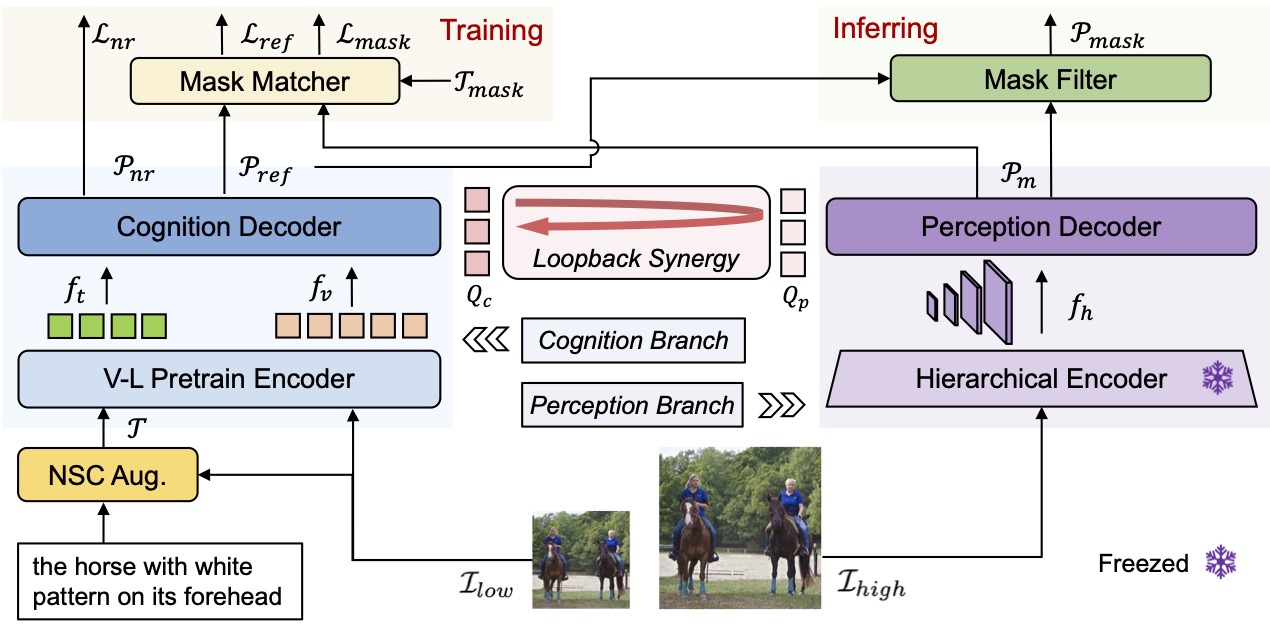
- 2026.06: 🎉 MomentSeg has been accepted to ECCV 2026. The project page and code are publicly available.
- 2026.03: 🎉 VideoSEG-O3 has been accepted to ICML 2026. The code is publicly available.
- 2026.02: 🎉 DeRVOS has been accepted to CVPR 2026.
- 2026.01: 🎉 DRL has been accepted to Pattern Recognition. The code is publicly available.
- 2025.11: 🎉 GC3VG, an extension of C3VG, has been accepted to TCSVT 2025.
- 2025.09: 🎉 InstanceVG has been accepted to TPAMI 2025. The code is publicly available.
- 2025.07: 🎉 Two papers have been accepted to ICCV 2025: PropVG and DeRIS. The code for PropVG and DeRIS is publicly available.
- 2024.12: 🎉 C3VG has been accepted to AAAI 2025 as an oral presentation. The code is publicly available.
- 2024.09: 🎉 SimVG has been accepted to NeurIPS 2024. The code is publicly available.
- 2023.12: 🎉 DenseUAV has been accepted to TIP 2023. The code is publicly available.
- 2021.09: 🎉 FSRA has been accepted to TCSVT 2021. The code is publicly available.
📝 Publications
Research Direction 1: Multimodal Agentic Search
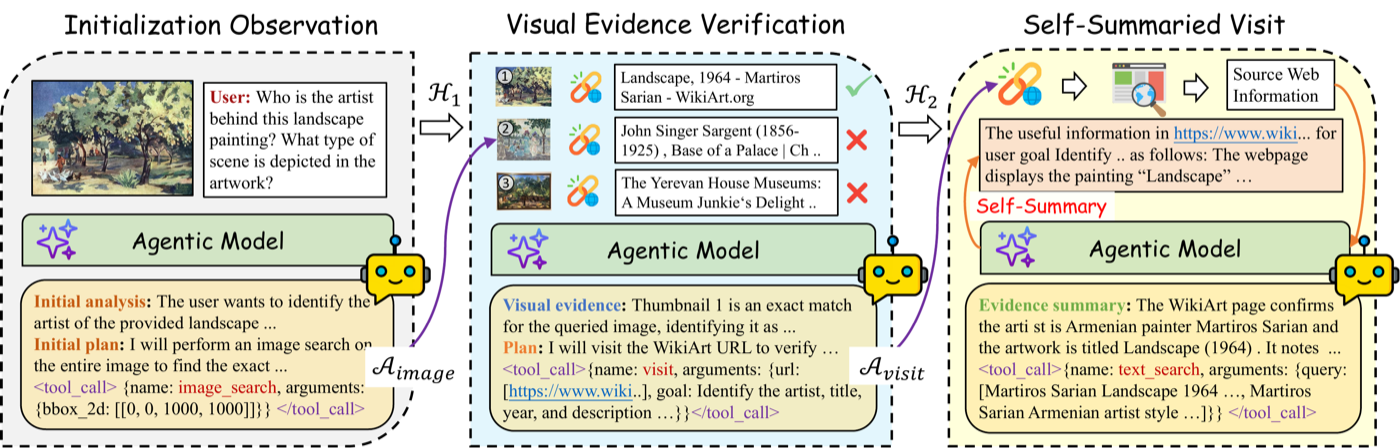

Highlights
Highlights: SimpleSearch-VL is an efficient, reliable, and practical framework for multimodal agentic deep search.
It improves the agent’s search-and-verification process with Factorized Adaptive Rollout, evidence-verified reasoning, and self-summarized visits, achieving strong search behavior from only 5K SFT trajectories and 2K RL prompts.
Research Direction 2: Referring/Reasoning Video Object Segmentation (RVOS)

Highlights
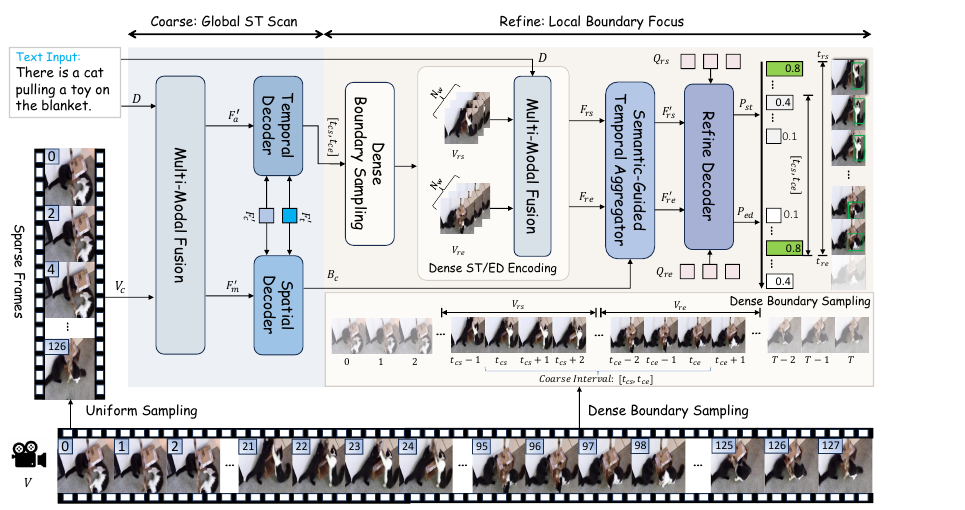
Highlights: ScanFocus is a coarse-to-fine framework for spatio-temporal video grounding, decoupling global spatio-temporal scanning from local boundary refinement.
It introduces Deformable Semantic-Motion Fusion for coarse proposal generation and SGTA for dense boundary-focused temporal modeling, improving precise timestamp regression.
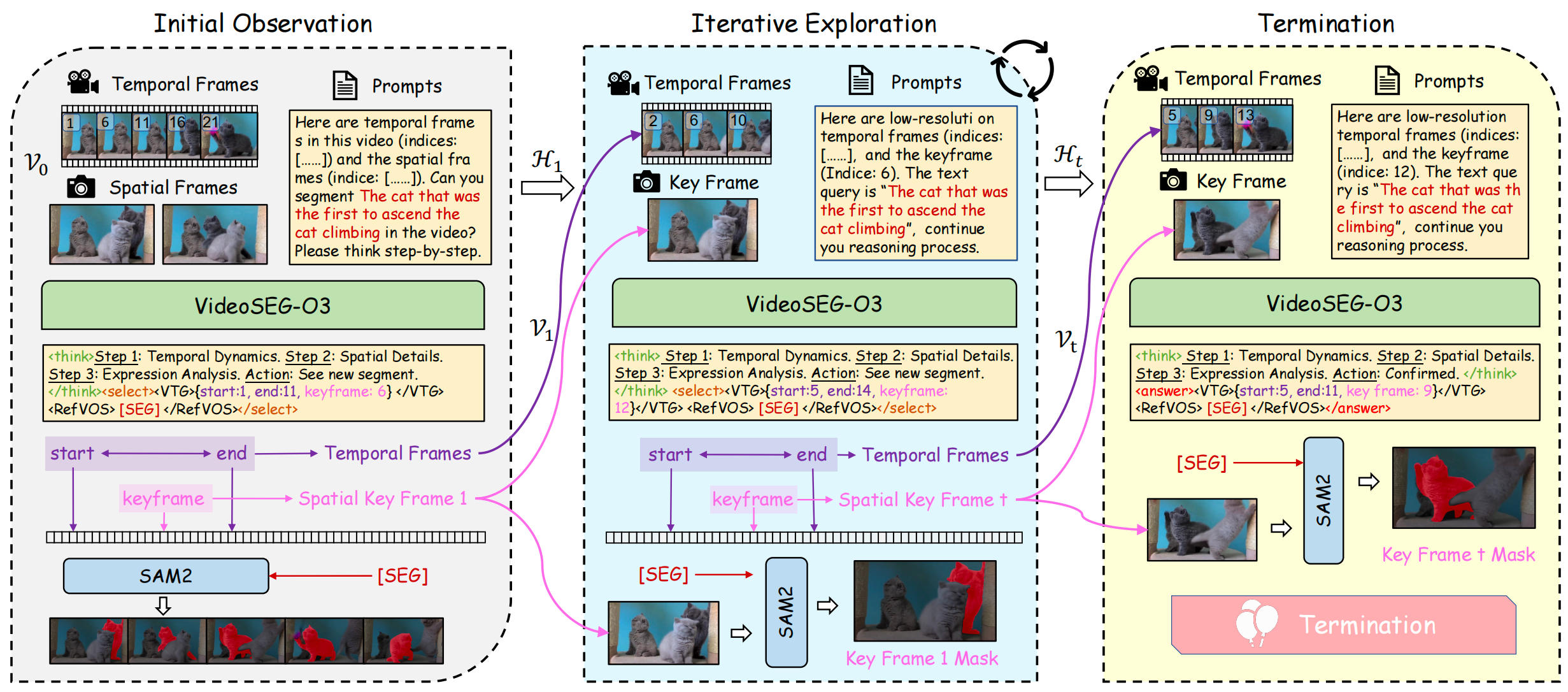

Highlights
Highlights: VideoSEG-O3 is a multi-turn RL framework for RVOS, actively exploring temporal intervals and keyframes through temporal-spatial CoT instead of relying on fixed sampled frames.
It further introduces SEG-aware logit calibration and a decoupled thinking trace, aligning token-level policy optimization with pixel-level mask quality.
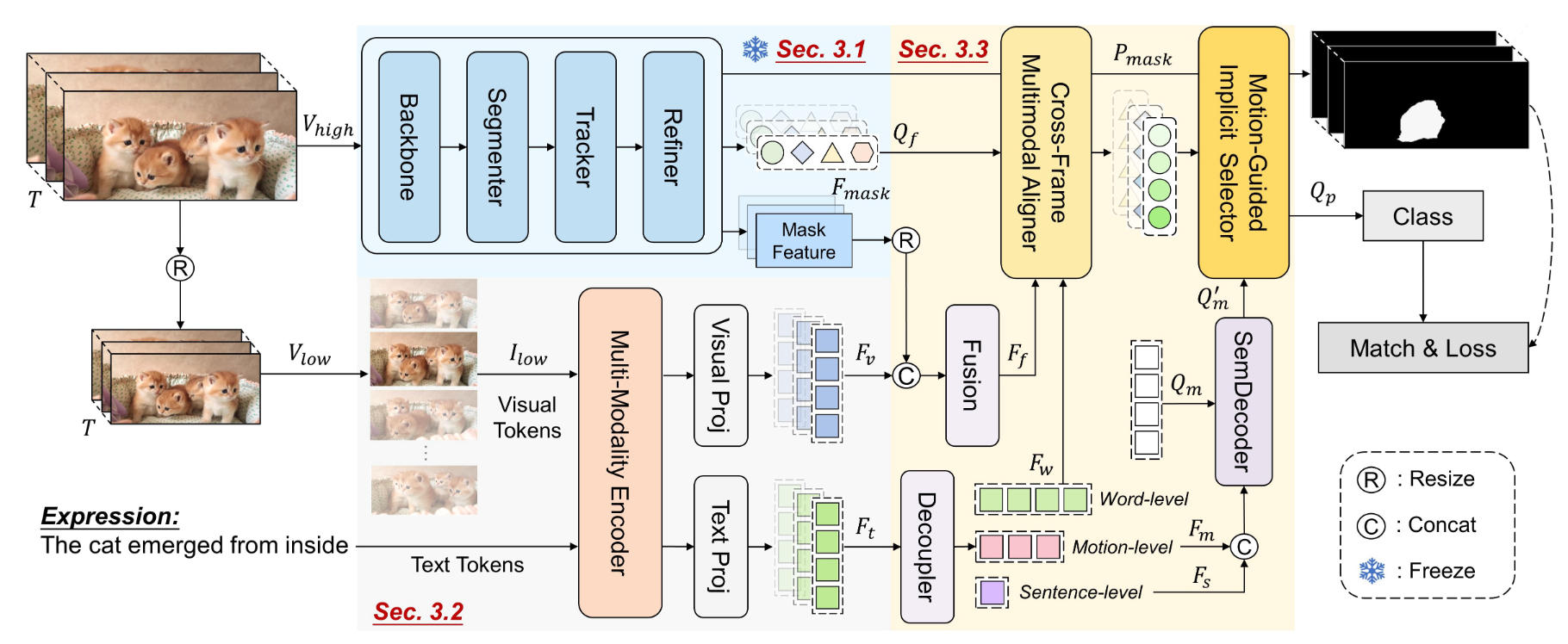
Highlights
Highlights: DeRVOS decouples trajectory generation and multimodal understanding, with TAIS aligning and selecting instance trajectories for robust RVOS.
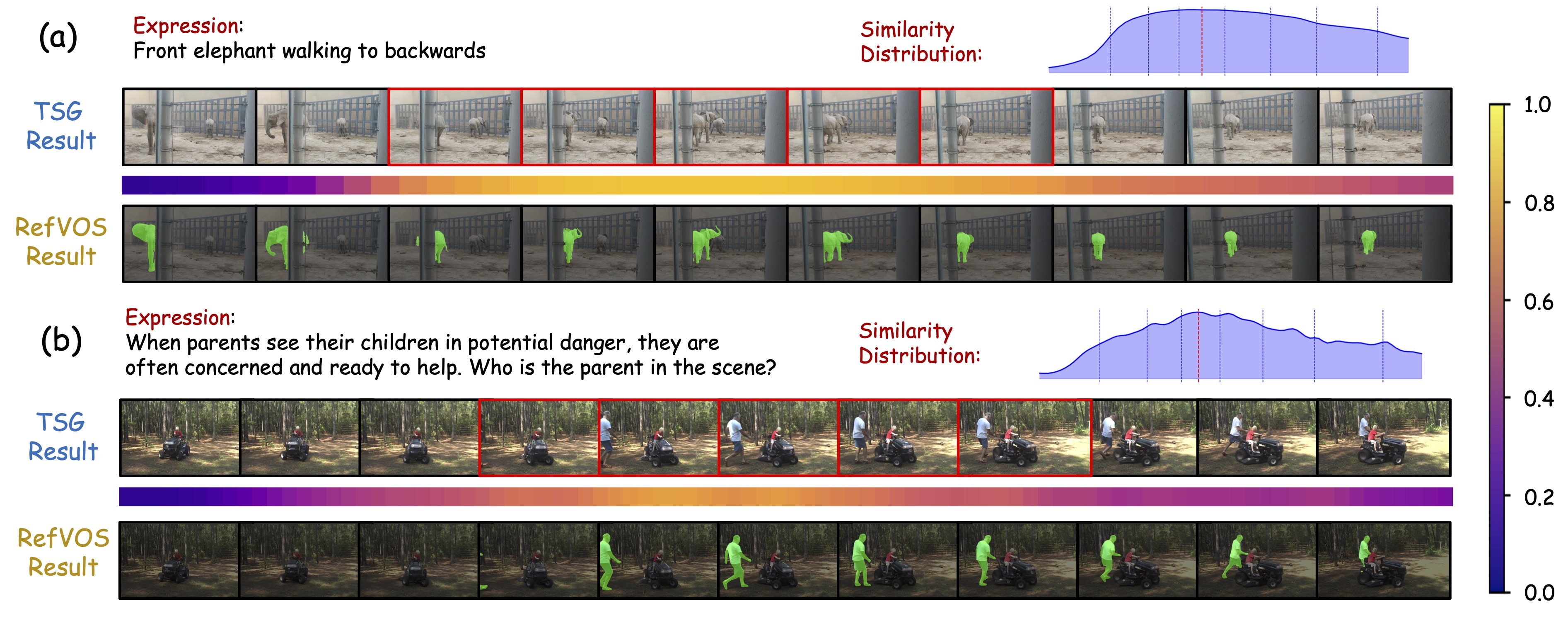

Highlights
Highlights: MomentSeg is a MLLM method, which unifies temporal grounding and segmentation, enabling key-frame extraction without relying on any external models.
In addition, we introduce a novel [FIND] token, which allows the model to perform temporal grounding without requiring any additional timestamp encoding.
Research Direction 3: Visual Grounding (REC, RES, GREC, GRES)
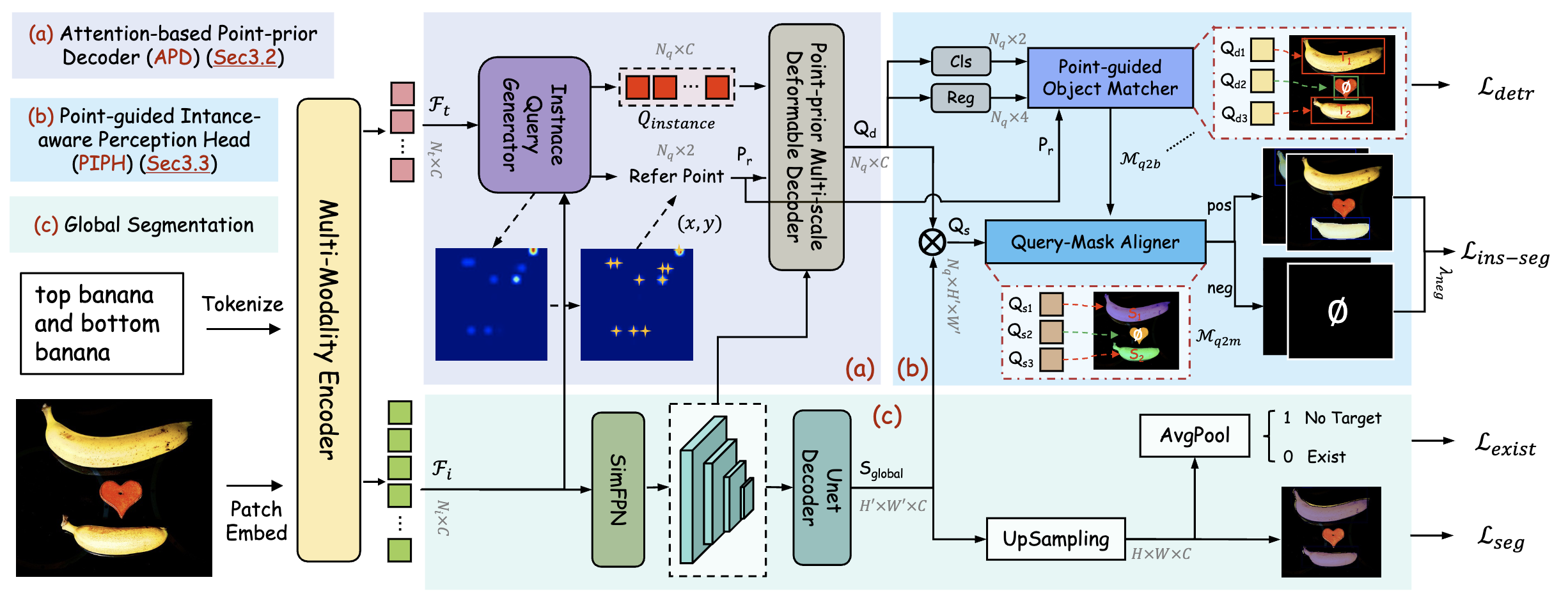

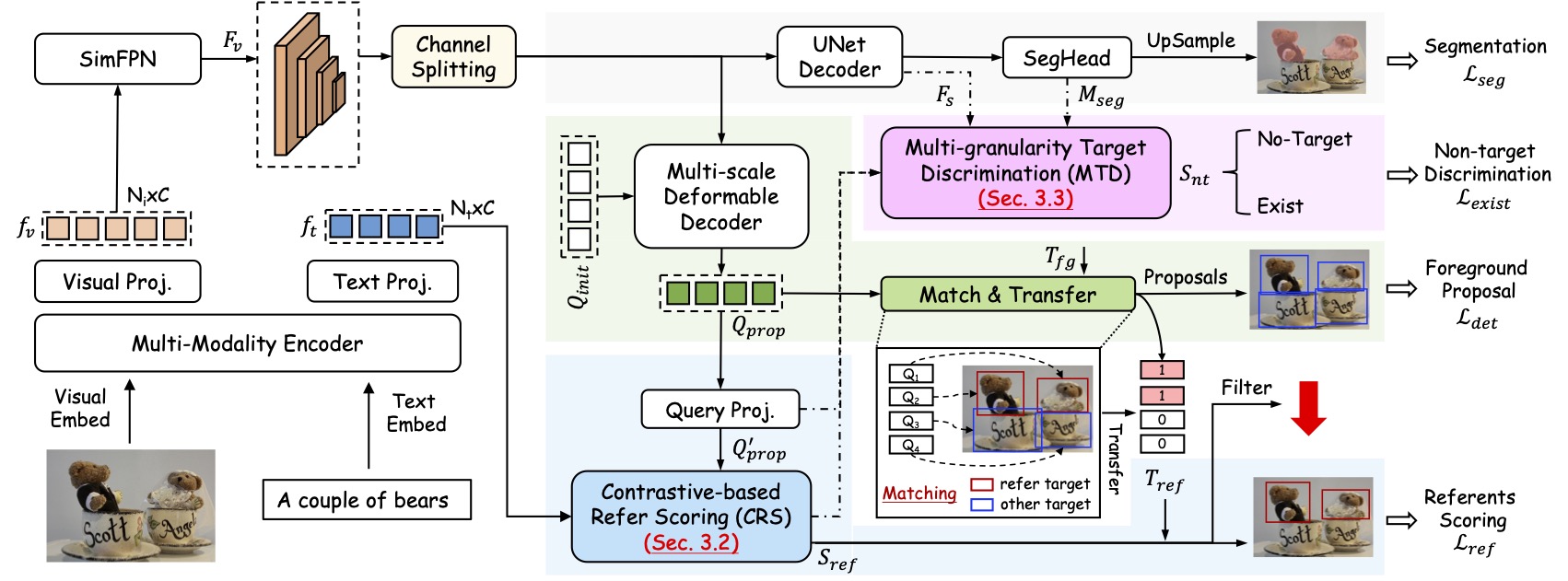


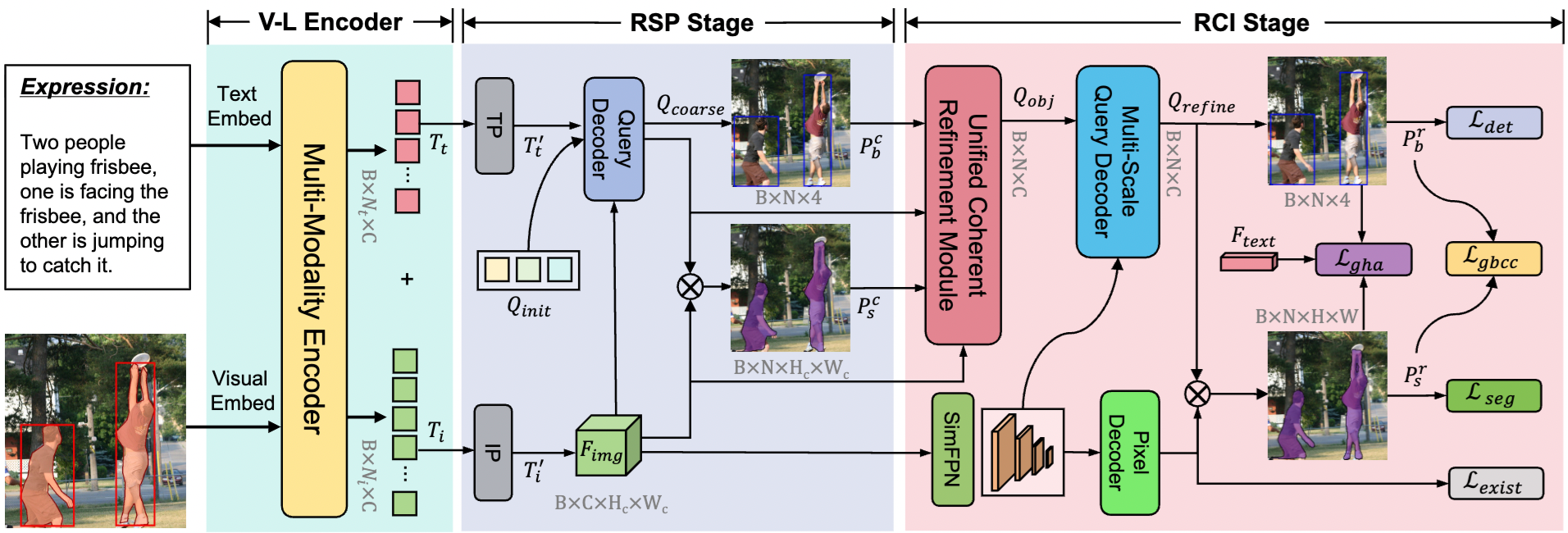
Highlights
Highlights: GC3VG generalizes the C3VG architecture and incorporates UCRM, which implicitly captures region/instance features and explicitly aligns them via an IoU-based relational constraint. The GHA strategy ensures feature-space consistency and boosts the discriminative strength of multi-modal representations.
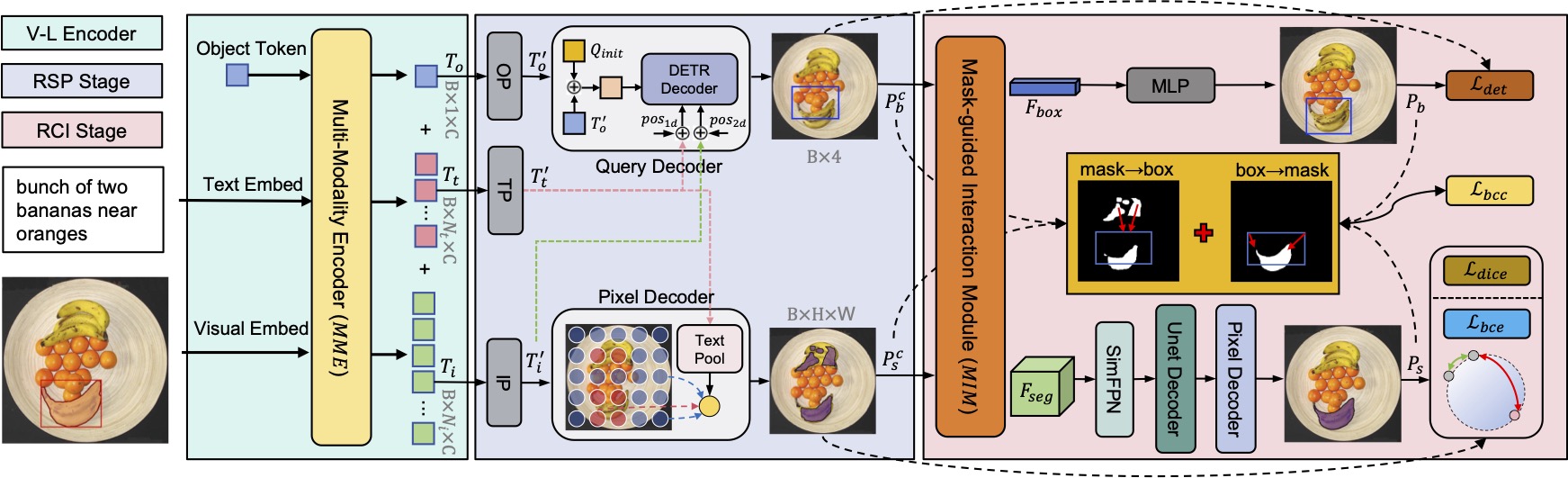


Highlights
Highlights: SimVG explores the importance of multi-modal understanding for the VG task, proposing a simple yet effective framework. It also adopts a synchronized distillation learning strategy between the teacher and student branches, enhancing the performance of the student branch.
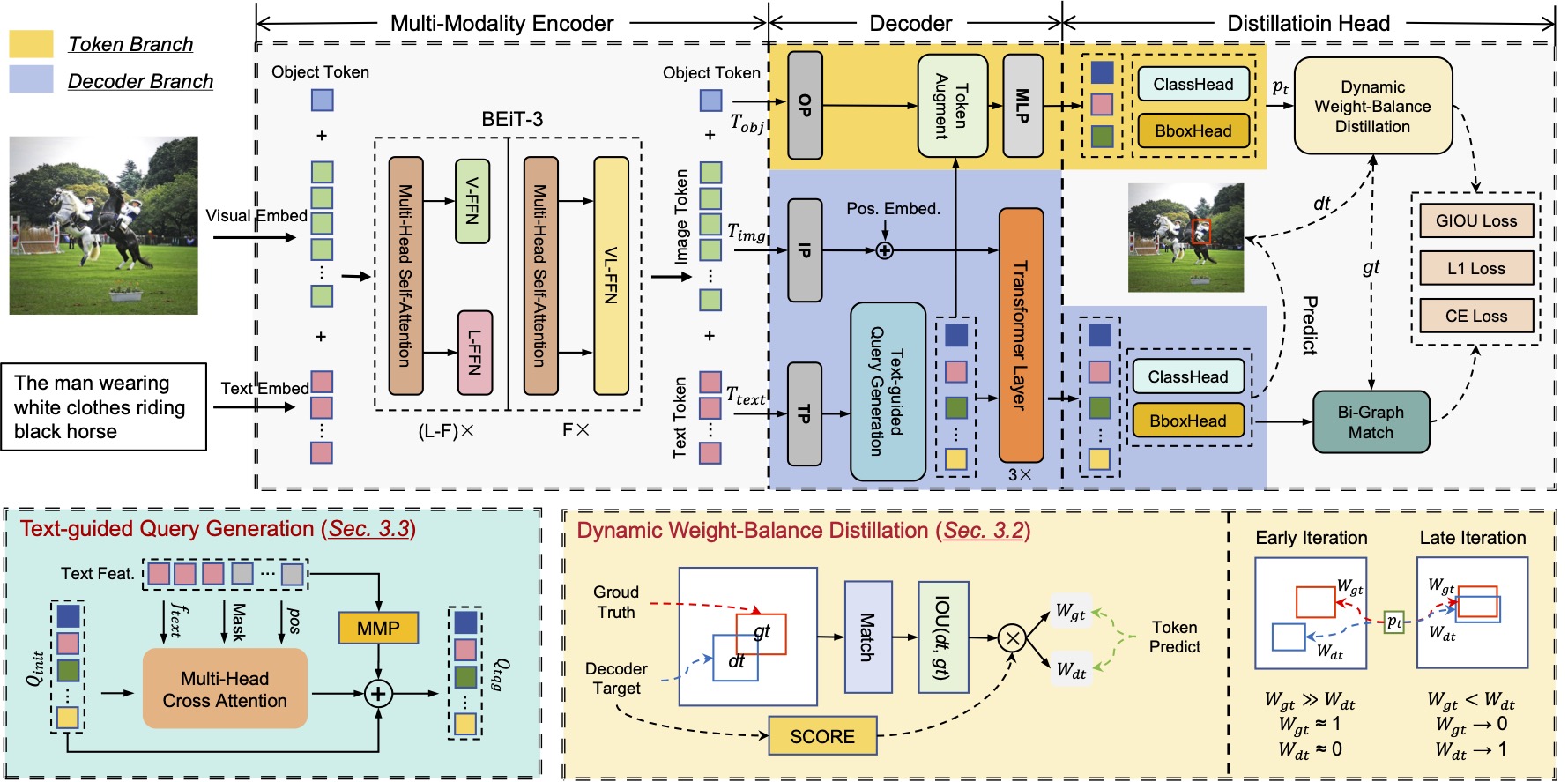
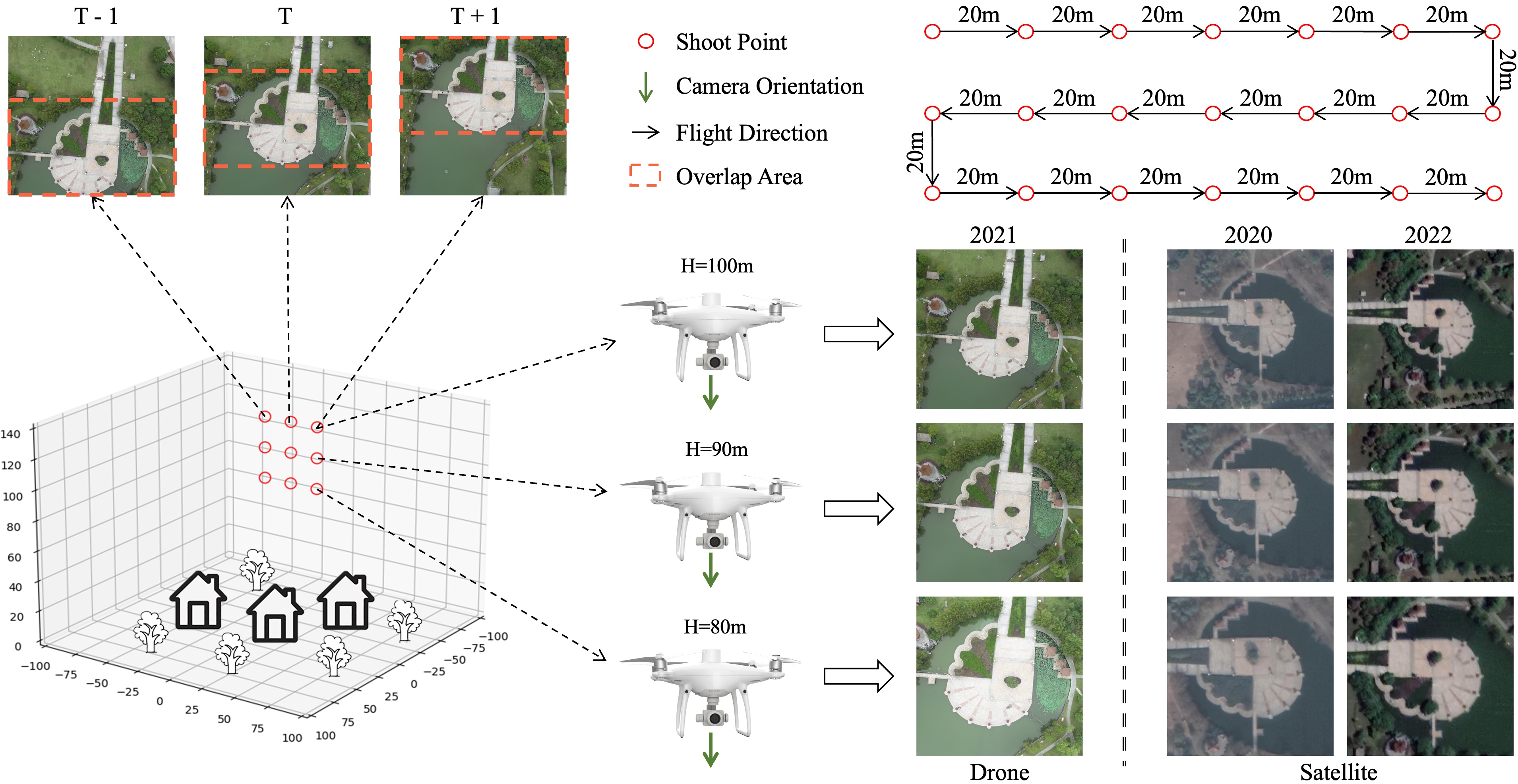
Research Direction 4: Cross-View Geo-Localization





🎖 Honors and Awards
Competition
- 2023.12 National First Prize, 5th Global Campus AI Algorithm Elite Competition (Zero-Shot Referring Expression Understanding)
- 2023.10 National First Prize (Champion), 4th “Space Cup” National Innovation and Creativity Competition (Multispectral Object Detection), Team Leader
- 2022.08 National Second Prize (Runner-up), China Postgraduate Smart City Technology and Creative Design Competition (Object Detection), Team Leader
- 2018.09 Zhejiang Provincial Robotics Competition: 2nd Prize (Shopping Track), 2nd Prize (Tourism Track), 3rd Prize (Transportation Track)
- 2017.09 1st Prize (East China Division) and 2nd Prize (National Division), Siemens Cup China Intelligent Manufacturing Challenge, Team Leader
Scholarships and Honors
- 2025 National Scholarship for Doctoral Students, Advanced Academic Individual, Southeast University
- 2022 National Scholarship for Graduate Students
- 2020 Outstanding Graduate of Zhejiang Province, Outstanding Undergraduate Graduate of China Jiliang University
- 2018 Zhejiang Provincial Government Scholarship
📖 Educations
-
 2023.09 – present Ph.D. Student, School of Automation, Southeast University, Nanjing, China.
2023.09 – present Ph.D. Student, School of Automation, Southeast University, Nanjing, China.
-
 2020.09 – 2023.06 Master’s Student, China Jiliang University, Hangzhou, China.
2020.09 – 2023.06 Master’s Student, China Jiliang University, Hangzhou, China.
-
2016.09 – 2020.06 Undergraduate Student, China Jiliang University, Hangzhou, China.
💻 Internships
-
 2026.03 – current Ant Group, Agent Research, Hangzhou, China
2026.03 – current Ant Group, Agent Research, Hangzhou, China
-
 2024.12 – 2026.02 Baidu, LMMs Research, Shanghai, China
2024.12 – 2026.02 Baidu, LMMs Research, Shanghai, China
-
 2022.11 – 2023.05 NIO, Autonomous Driving – Algorithm, Beijing, China
2022.11 – 2023.05 NIO, Autonomous Driving – Algorithm, Beijing, China
-
 2022.03 – 2022.08 ByteDance, E-commerce – Algorithm, Hangzhou, China
2022.03 – 2022.08 ByteDance, E-commerce – Algorithm, Hangzhou, China
💬 Services
Reviewers
- TIP, TNNLS, TCSVT, ISPRS, PR
- NeurIPS2025, CVPR2025, ICCV2025, AAAI2026, ICLR2026, CVPR2026, ICML2026, ECCV2026
Leadership
- 2018–2019 President, 1st AI and Robotics Association, China Jiliang University